
Duplicate content : la définition claire qui évite les erreurs coûteuses
Le duplicate content SEO désigne tout texte identique ou très similaire accessible depuis plusieurs URLs, qu'elles appartiennent à un même site ou à des sites différents. Google ne fixe pas de seuil officiel, mais l'observation des audits sur des sites de PME montre qu'au-delà de 80 % de similarité, l'algorithme considère les deux pages comme un même contenu. Cette notion est devenue centrale depuis la mise à jour Helpful Content de Google, qui privilégie systématiquement l'originalité, l'expertise et la profondeur éditoriale au détriment des contenus répétitifs ou paraphrasés.
Pour comprendre l'enjeu, il faut visualiser la situation du point de vue de Google : lorsqu'il rencontre deux pages qui racontent presque la même chose, il ne sait plus laquelle proposer à l'internaute. Il choisit alors une seule version, écarte les autres de son index principal et redistribue silencieusement les positions. Le résultat se traduit par une perte de visibilité progressive, sans alerte explicite dans la Search Console.
Le duplicate content expliqué visuellement
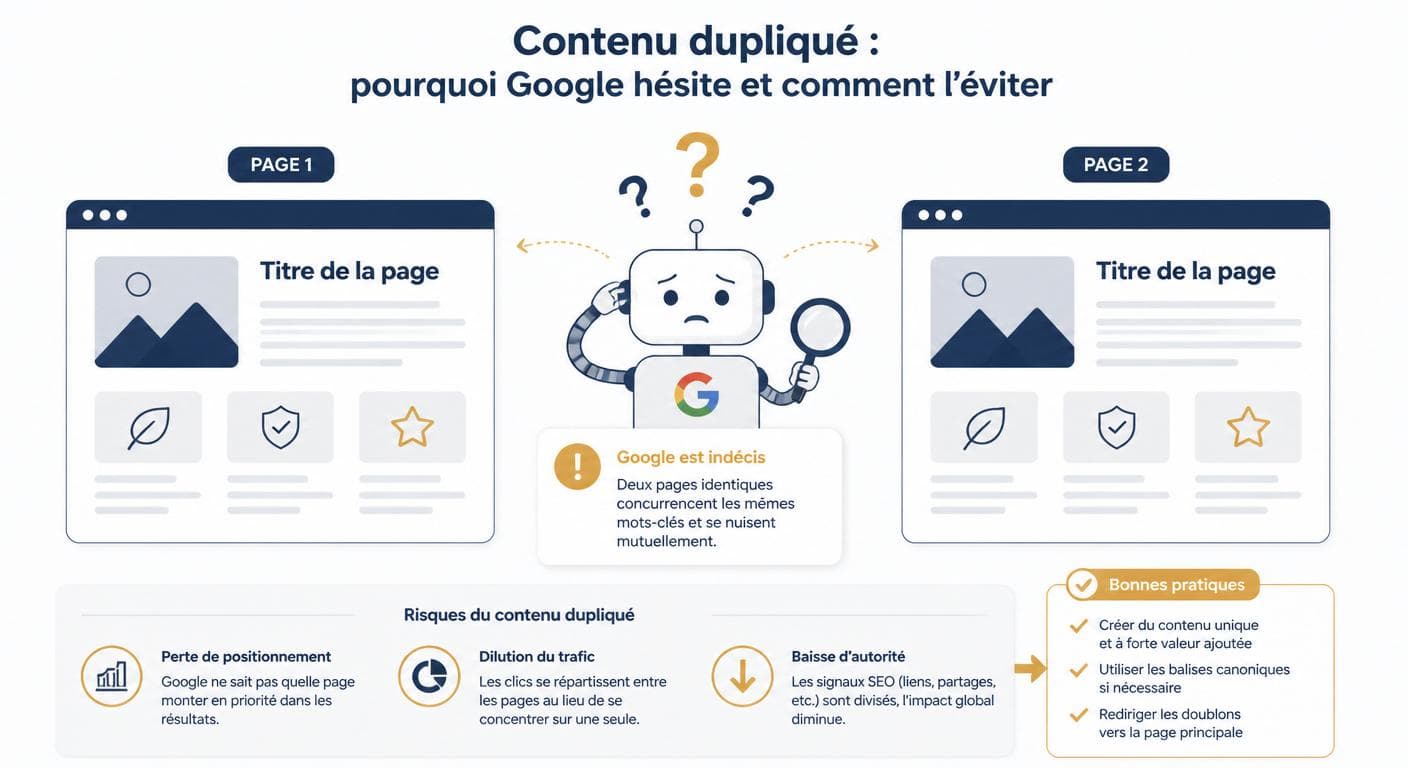
Cette dilution silencieuse explique pourquoi tant de sites professionnels souffrent d'une stagnation inexpliquée : le travail éditorial existe, mais il se neutralise lui-même. Avant d'entrer dans le détail des causes et des remèdes, fixons quelques repères de vocabulaire qui reviendront tout au long de ce guide : URL canonique (la version officielle d'une page que vous désignez à Google), indexation (l'inscription d'une page dans la base de données de Google), crawl (le passage des robots qui explorent votre site), et signal de qualité (tout élément technique ou éditorial qui aide Google à juger la valeur d'une page).
Conseil du coach
Définition technique selon Google
La documentation officielle de Google Search Central définit le duplicate content google comme « des blocs substantiels de contenu, à l'intérieur d'un même domaine ou entre domaines, qui correspondent entièrement ou sont sensiblement similaires ». Cette formulation introduit deux notions clés : le contenu strictement identique (copier-coller pur) et le contenu fortement similaire (paraphrase, simple changement de ville, traduction automatique). Pour traiter ces cas, Google regroupe les URLs concernées dans ce que les ingénieurs appellent un cluster d'URLs : un ensemble de pages jugées équivalentes dont une seule sera choisie pour représenter le contenu dans les résultats.
La traduction en langage client
Imaginez un libraire qui reçoit deux exemplaires identiques d'un même livre : il les range au même endroit, met l'un en rayon et stocke l'autre en réserve. Google fonctionne pareil. Si vous publiez une page « plombier Nantes » et une page « plombier Saint-Herblain » construites avec exactement les mêmes phrases, Google conservera l'une et reléguera l'autre. Ce contenu dupliqué référencement ne pénalise pas brutalement votre site, il vous prive simplement de la moitié de votre potentiel de visibilité locale, sans bruit ni alerte.
Pourquoi cette notion devient critique en 2026
L'explosion du contenu publié en ligne, accentuée par les outils de génération automatique, oblige Google à durcir ses critères de tri. La duplication de contenu seo est désormais l'un des premiers signaux qui dégradent la perception de qualité d'un domaine entier. Cette évolution rejoint le cadre E-E-A-T (Expérience, Expertise, Autorité, Confiance) : un site qui répète ses propres contenus ou paraphrase ceux des concurrents perd sur les quatre dimensions à la fois. Pour les professions libérales, artisans et commerçants locaux, cela signifie qu'un site générique, même bien construit techniquement, n'a presque plus aucune chance de percer dans les pages locales sans un effort d'originalité éditoriale.
Comment Google détecte et sanctionne le contenu dupliqué
Pour comprendre comment se protéger, il faut savoir ce qui se passe côté Google quand ses robots croisent deux pages similaires. Le moteur ne procède pas à un jugement humain : il applique une suite d'algorithmes qui comparent, regroupent et choisissent. Le duplicate content google entre alors dans un pipeline en trois étapes — détection, choix canonique, déclassement — qui se déroule sans alerte visible pour le propriétaire du site. Comprendre ce pipeline est essentiel pour anticiper les décisions de l'algorithme et éviter qu'elles soient défavorables.
Les 3 étapes de la réaction de Google
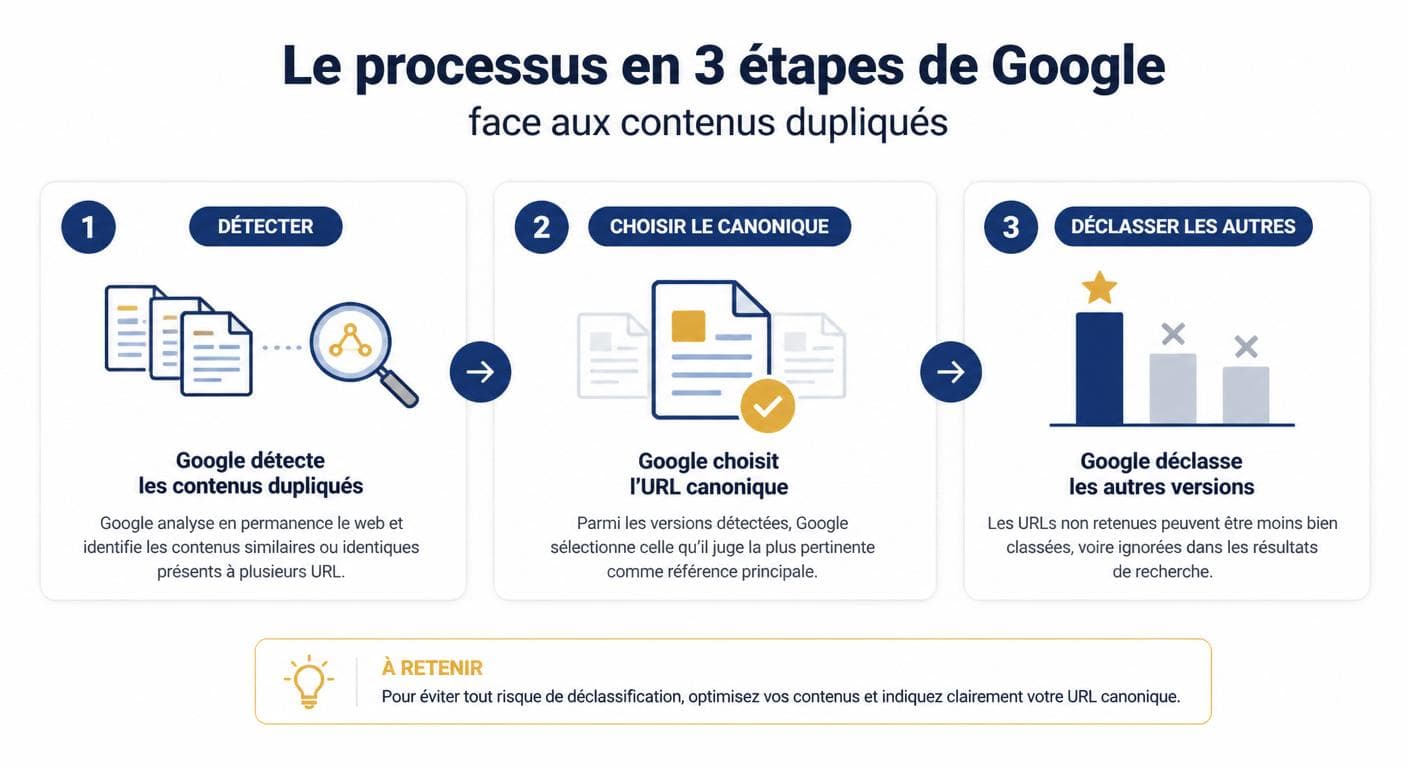
Dans la pratique, Google adopte trois niveaux de réponse selon la gravité et le volume de duplication détectés. Le premier niveau est l'indifférence apparente : Google détecte le doublon, choisit une version canonique et laisse l'autre en sommeil dans son index secondaire. Le deuxième niveau est la désindexation silencieuse d'une ou plusieurs versions, ce qui se traduit par une baisse de pages indexées dans la Search Console. Le troisième niveau, beaucoup plus rare, est l'action manuelle explicite, réservée aux cas extrêmes de plagiat massif ou de réseaux de sites miroirs.
Les 3 niveaux de réaction de Google face au duplicate content
| Niveau de réaction | Déclencheur typique | Fréquence observée | Conséquence visible |
|---|---|---|---|
| Ignorer / clusteriser | Doublons techniques d'URL (www, slash, paramètres) | ~70 % des cas | Une seule version dans Google, autres absentes |
| Désindexer une version | Pages très similaires sans canonique déclarée | ~25 % des cas | Baisse du nombre de pages indexées |
| Action manuelle | Plagiat massif, sites miroirs, scraping industriel | <5 % des cas | Notification dans Search Console |
Conseil du coach
Le fingerprinting algorithmique
Google compare les pages grâce à une technique appelée shingling : il découpe chaque texte en blocs de plusieurs mots consécutifs (les shingles), puis calcule une empreinte numérique unique pour chaque page. Deux pages avec des empreintes proches sont considérées comme des doublons. Cette méthode explique pourquoi il ne suffit plus de reformuler 30 % d'un texte pour échapper à la détection : si la structure des phrases, l'ordre des arguments et le vocabulaire restent identiques, l'empreinte reste proche. Le duplicate content seo se règle donc par une réécriture en profondeur, pas par une simple substitution de synonymes.
Le choix automatique de l'URL canonique
Quand vous ne déclarez pas explicitement votre URL canonique, Google la choisit pour vous. Il s'appuie sur plusieurs signaux : autorité de la page (nombre et qualité des liens entrants), ancienneté dans l'index, profondeur dans l'arborescence du site, présence dans le sitemap, cohérence du maillage interne. Le problème est que ce choix peut être contraire à votre stratégie : Google peut désigner une page secondaire avec quelques backlinks comme version principale, au détriment de la page commerciale que vous vouliez positionner. Pour reprendre la main, la balise canonical est l'outil le plus simple et le plus efficace.
La différence entre filtre algorithmique et action manuelle
Le rapport « Indexation des pages » de la Search Console distingue clairement les deux situations. La mention « Page en double sans canonique sélectionnée par l'utilisateur » indique un filtre algorithmique : Google a détecté un doublon et choisit lui-même la version à indexer. La mention « Variante avec balise canonique différente » signale que Google n'a pas suivi votre canonique parce qu'il juge la page cible non équivalente. Le duplicate content et pénalité google dans son sens strict (action manuelle) apparaît dans la section « Actions manuelles » et reste exceptionnel. La grande majorité des problèmes que rencontrent les sites de PME relèvent du filtre algorithmique invisible.
Les 6 formes de contenu dupliqué qui plombent votre visibilité
La duplication de contenu seo ne se limite pas au copier-coller volontaire. Sur les audits réalisés par notre équipe pour des professions libérales et des artisans, six formes reviennent systématiquement. Chacune produit un effet différent sur le référencement, demande une correction spécifique et présente un niveau de risque variable selon le secteur. Cette typologie permet d'orienter immédiatement l'audit vers les zones qui produiront le plus de gain.
Les 6 formes de duplicate content
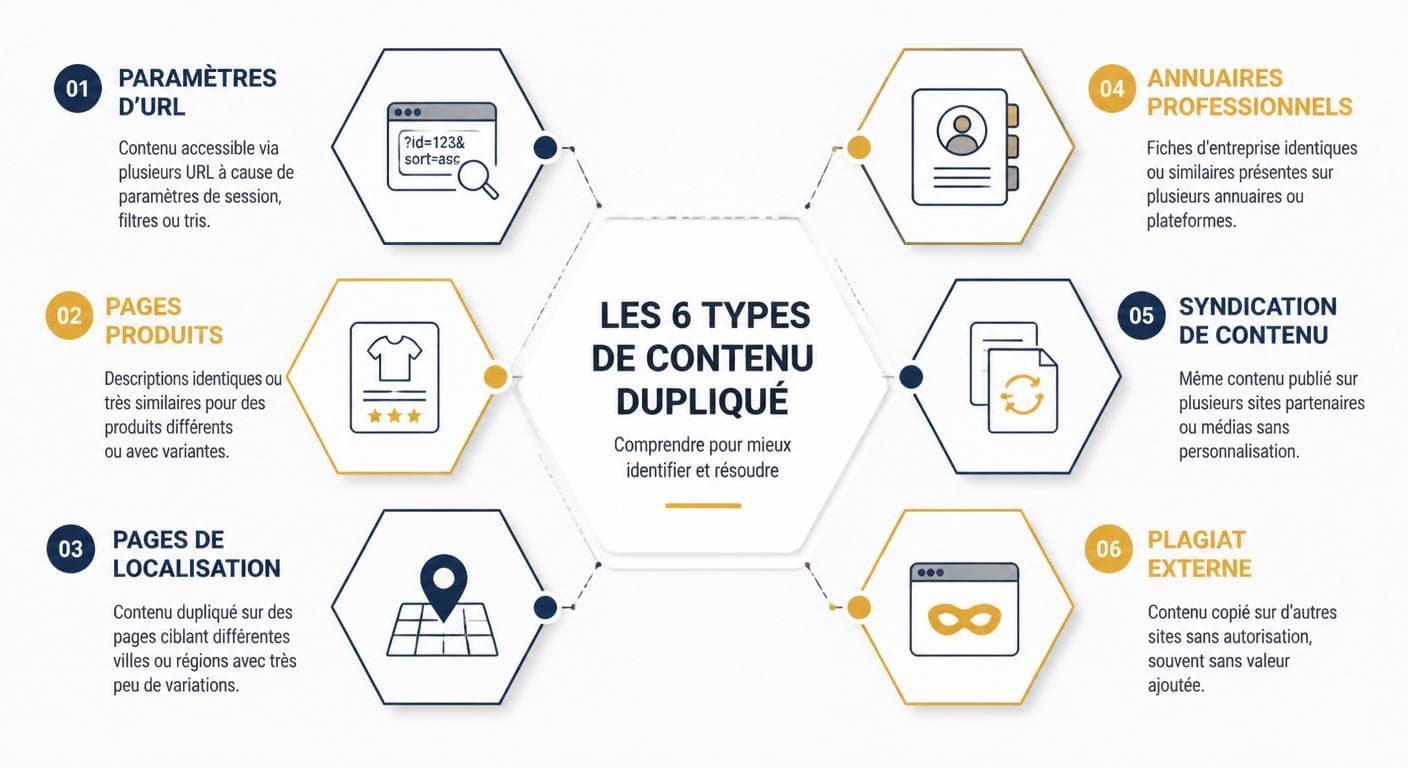
Les 6 formes de duplicate content et leur criticité
| Type | Exemple métier | Risque SEO | Correction prioritaire |
|---|---|---|---|
| Doublons techniques d'URL | http/https, www, slash final, UTM | Élevé (volume) | Redirections 301 + canonical |
| Fiches produits ou prestations clonées | Boutique e-commerce, cabinet médical | Moyen à élevé | Réécriture individuelle |
| Pages métier + ville | Plombier Nantes / Plombier Rezé | Élevé en local | Ancrage local réel |
| Site et annuaires professionnels | Doctolib, PagesJaunes, ordres | Moyen | Description différente partout |
| Syndication mal attribuée | Republication blog + LinkedIn + Medium | Moyen | Balise canonical cross-domain |
| Plagiat externe subi | Concurrent qui copie vos textes | Faible à moyen | Signalement DMCA |
Conseil du coach
Doublons techniques d'URL
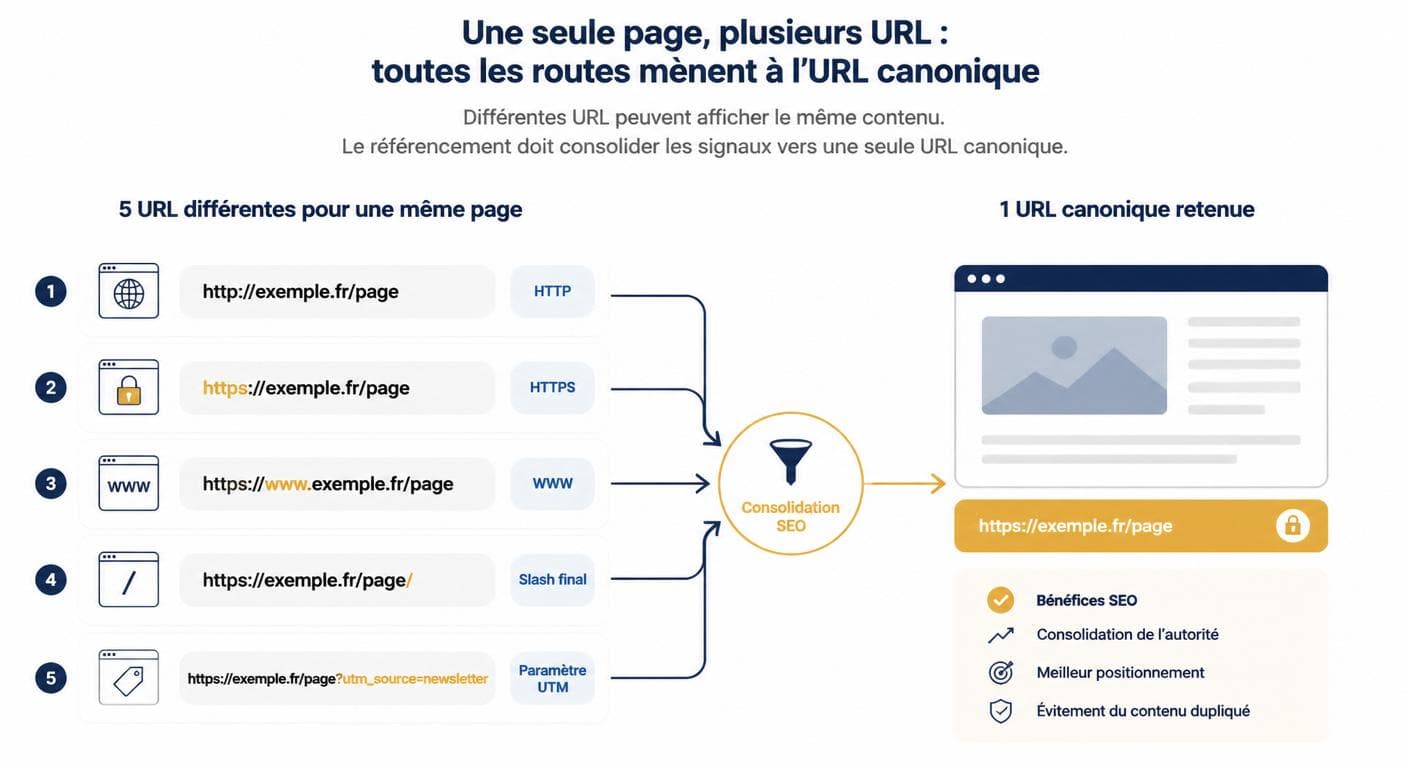
Une même page peut être accessible via plusieurs adresses sans que vous l'ayez voulu : http://monsite.fr/contact, https://monsite.fr/contact, https://www.monsite.fr/contact, https://www.monsite.fr/contact/ (avec slash final), https://www.monsite.fr/contact?utm_source=newsletter. Pour Google, ce sont cinq URLs distinctes et donc cinq versions potentiellement dupliquées. À cela s'ajoutent les identifiants de session générés par certains CMS, l'ordre alphabétique des paramètres et les versions imprimables. Sur un site vitrine standard, ces variantes peuvent créer mécaniquement 200 à 500 URLs dupliquées pour 30 pages réelles.
La correction passe par trois actions complémentaires : forcer le HTTPS via une redirection 301, choisir entre www et non-www puis rediriger l'autre, et déclarer la version canonique sur chaque page. Ces trois réflexes traitent à eux seuls la majorité des problèmes de duplicate content seo rencontrés sur des sites de PME.
Cinq URLs, une seule page
Fiches produits ou prestations clonées
Le cas le plus fréquent en e-commerce concerne les descriptions fournies par le fabricant et reprises telles quelles par plusieurs revendeurs : votre fiche produit devient instantanément un doublon de centaines d'autres. Pour gérer le contenu dupliqué d'une boutique e-commerce, la règle est de réécrire chaque fiche avec un angle propre : usage concret, conseil d'expert, comparaison avec un produit similaire, retour client vérifié. Le même piège existe pour les professions libérales qui dupliquent leur page « consultation » en changeant seulement le nom de la spécialité : une page kinésithérapie générale et une page kinésithérapie du sport doivent décrire des parcours, des indications et des protocoles distincts.
Pages locales « métier + ville »
C'est le piège classique du référencement local. Vous voulez apparaître sur dix villes autour de votre siège, alors vous créez dix pages avec le même texte et vous changez juste le nom de la commune. Google identifie immédiatement le contenu dupliqué sur un site avec plusieurs implantations géographiques et ne garde qu'une seule de ces pages dans son index, en général celle qu'il juge la plus représentative. Le travail consiste à individualiser chaque page locale avec des éléments qui ne se trouvent nulle part ailleurs : références clients de la zone, témoignages géolocalisés, mention des quartiers et des particularités urbaines, partenariats locaux, retours d'expérience sur des chantiers ou des consultations spécifiques à la ville. C'est ce travail d'ancrage qui fait passer une page locale du statut de doublon à celui de contenu utile.
Duplicate content et référencement local : le piège des professions libérales et artisans
Le contenu dupliqué et référencement local nantes angers est un sujet à part entière. La concurrence se joue sur un volume limité de mots-clés (votre métier × votre ville), avec un nombre restreint d'acteurs locaux. Un seul doublon mal géré peut faire basculer votre site derrière deux ou trois concurrents et neutraliser une stratégie locale entière. Le piège vient souvent d'une cohabitation mal pensée entre trois supports : votre site, votre fiche Google Business Profile et les annuaires professionnels (PagesJaunes, Doctolib, ordres). Tous ces supports parlent de la même entreprise, mais ils ne doivent surtout pas dire la même chose avec les mêmes mots.
Cohabitation site, Google Business Profile et annuaires
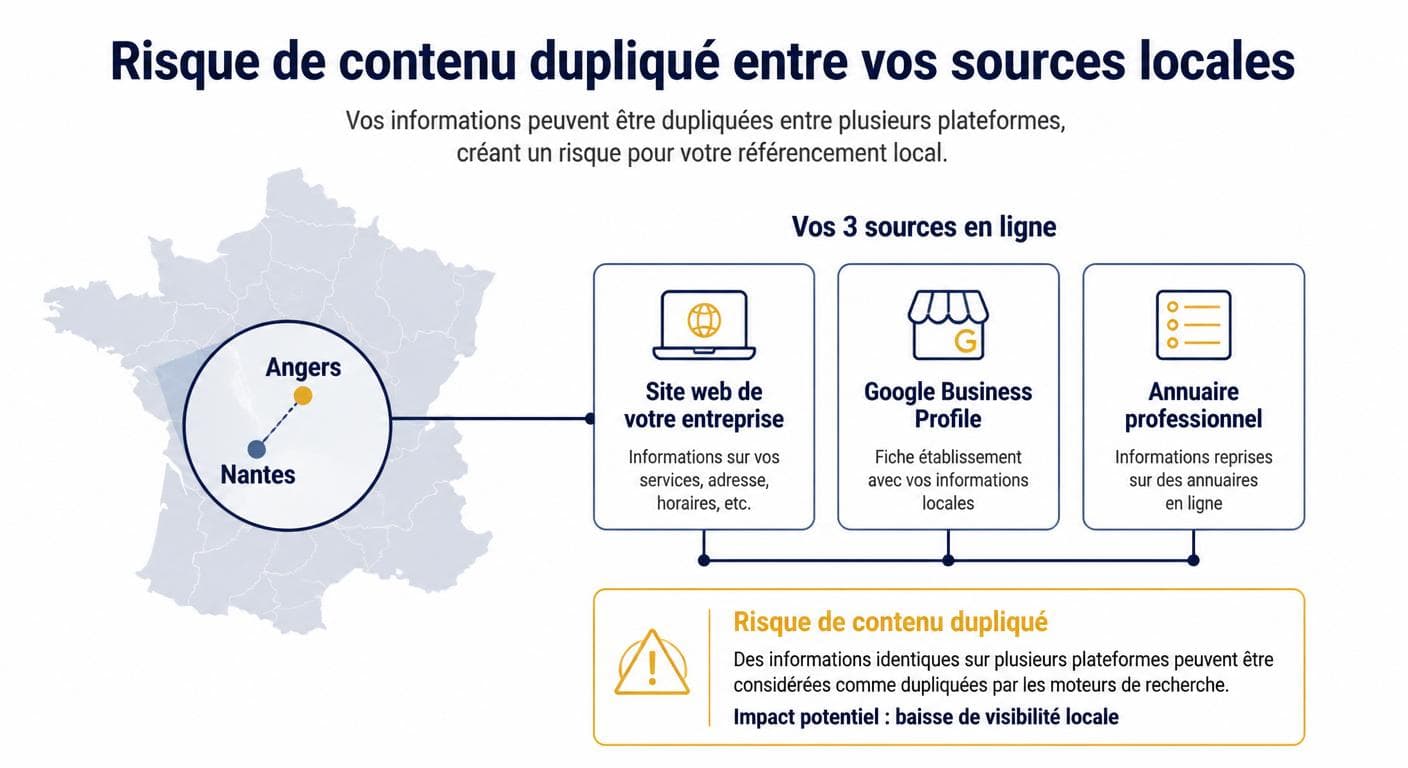
La règle de base est simple : la cohérence NAP (Nom, Adresse, Téléphone) doit être stricte et identique partout. En revanche, les textes éditoriaux — description de l'activité, services, présentation des praticiens, témoignages — doivent être uniques sur chaque support. Cette distinction est rarement comprise et constitue la source numéro un d'affaiblissement des pages locales. Pour aller plus loin sur ce sujet, consultez notre guide complet sur le référencement local.
Conseil du coach
Le risque caché site / fiche d'établissement
Officiellement, Google ne traite pas la fiche Google Business Profile comme une URL classique soumise au filtre duplicate content. Mais en pratique, une description recopiée mot pour mot entre la fiche et la page d'accueil du site affaiblit toujours la page locale. Pour gérer le contenu dupliqué et google business profile, la bonne pratique consiste à différencier l'angle de chaque support : la fiche met l'accent sur la proximité, les horaires, la zone d'intervention et le service immédiat ; le site développe l'expertise, les références, la méthode et les services dans le détail. Deux textes, deux fonctions, deux publics.
Pages multi-villes et cocon sémantique
Quand un artisan ou une profession libérale couvre plusieurs communes, la tentation de cloner les pages est forte. La méthode efficace consiste à construire un cocon sémantique local : une page mère sur le métier au niveau régional, et des pages filles par ville qui partagent la même structure mais qui ne partagent jamais le même texte. Sur un cocon plombier Nantes / plombier Saint-Herblain / plombier Rezé bien construit, chaque page comporte sa propre étude de cas, ses propres avis clients géolocalisés, ses particularités d'intervention (zones piétonnes, copropriétés du centre, lotissements récents). L'impact du contenu dupliqué sur le référencement local disparaît alors complètement, parce qu'il n'y a plus rien à dupliquer : chaque page raconte une histoire différente.
Annuaires professionnels et déontologie
Le plagiat seo peut aussi venir de votre propre présence sur des annuaires professionnels. Doctolib, PagesJaunes, Solocal, ordres professionnels : ces plateformes vous demandent une description, et beaucoup de praticiens recopient exactement le texte de leur site. Le risque immédiat n'est pas une pénalité, mais une cannibalisation : la fiche annuaire, souvent plus puissante en référencement, peut prendre la place de votre propre site sur certaines requêtes. La parade consiste à rédiger une version courte et distincte pour chaque annuaire, en gardant les services et l'identité de l'entreprise mais en variant les formulations, les mots-clés secondaires et la mise en avant. Quand la plateforme le permet, déclarer une balise canonical vers votre site renforce ce signal.
Détecter le contenu dupliqué : méthode complète et outils
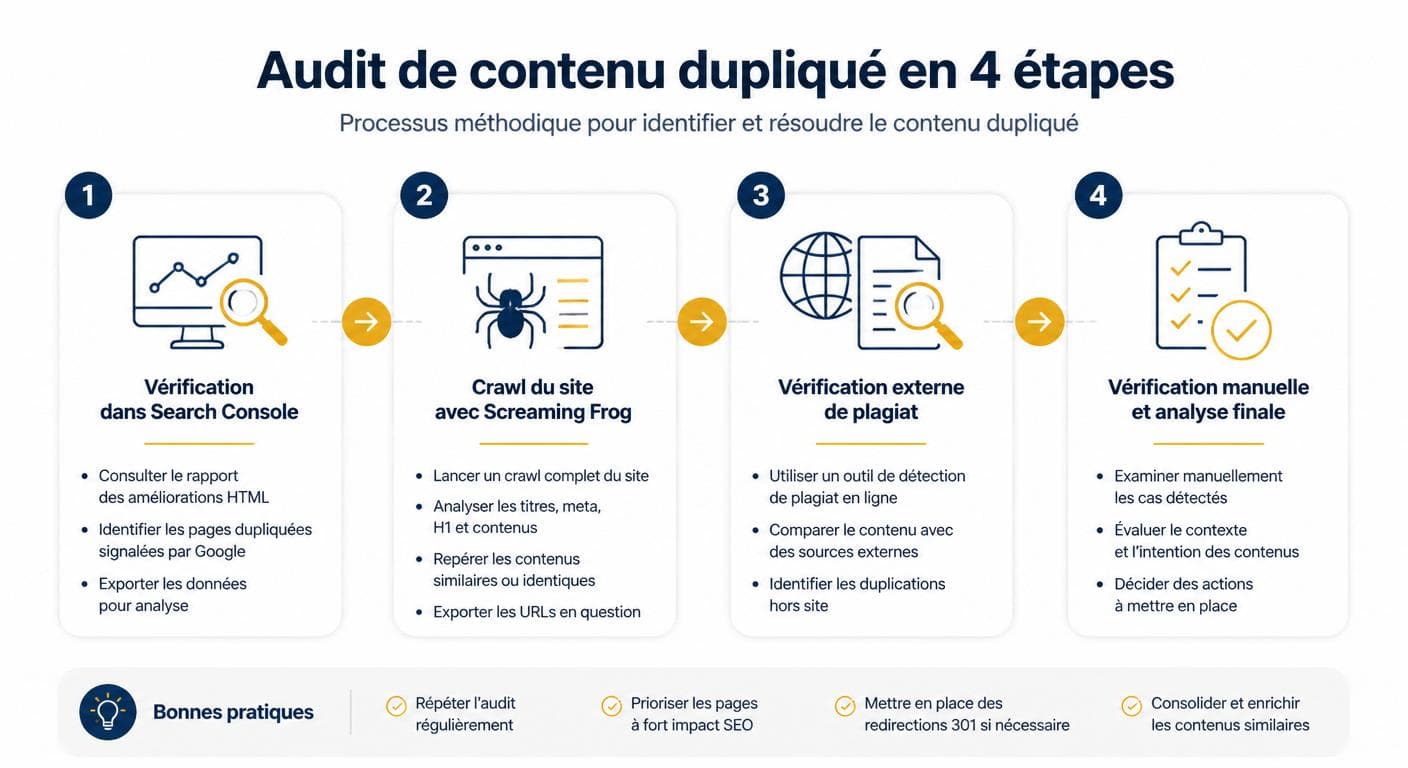
Savoir comment détecter le contenu dupliqué sur mon site est la première étape de tout audit sérieux. La méthode efficace combine quatre approches complémentaires : la lecture du rapport Search Console, le crawl interne, la vérification externe et le contrôle manuel sur les pages stratégiques. Chacune révèle un type de doublon différent et aucune ne se suffit à elle-même.
Méthode d'audit en 4 étapes
Comparatif des outils de détection de duplicate content
| Outil | Type de détection | Gratuit | Capacité | Cas d'usage recommandé |
|---|---|---|---|---|
| Google Search Console | Doublons identifiés par Google | Oui | Illimitée | Point de départ obligatoire |
| Siteliner | Similarités internes | Oui (250 pages) | Petits sites | Site vitrine TPE |
| Screaming Frog | Crawl complet + near duplicates | Partiel | 500 URLs gratuit, illimité payant | Sites 50+ pages |
| Copyscape | Plagiat externe | Partiel | Page par page | Vérification ponctuelle |
| Quetext | Plagiat externe + IA | Partiel | Volume modéré | Contenu éditorial |
| Kill Duplicate | Surveillance externe automatique | Non | Sites professionnels | Surveillance continue |
Conseil du coach
La Google Search Console comme point de départ
Le rapport Indexation des pages de la Search Console est l'outil le plus précieux pour comprendre la vision que Google a réellement de votre site. Dans la section « Pourquoi des pages ne sont pas indexées », deux catégories signalent directement le duplicate content google : « Page en double, Google a choisi une autre canonique que celle de l'utilisateur » et « Page en double sans canonique sélectionnée par l'utilisateur ». Exportez la liste au format CSV, triez par template d'URL pour identifier les patterns récurrents, et priorisez les pages avec le plus fort potentiel commercial. Cette première lecture donne en quelques minutes une image fidèle des chantiers à ouvrir.
Crawler son site avec Screaming Frog ou Siteliner
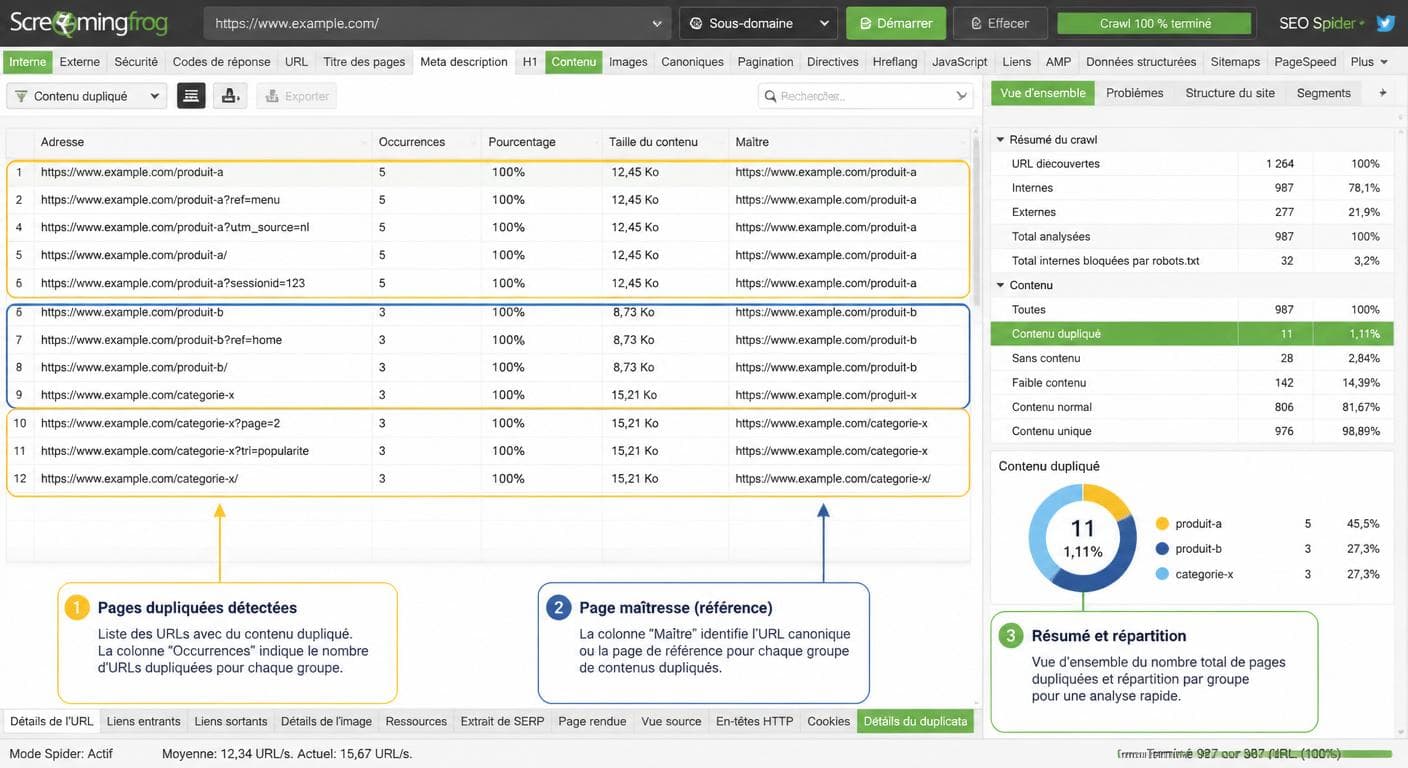
Pour aller plus loin et savoir précisément comment détecter le contenu dupliqué sur mon site, un crawl interne est indispensable. Screaming Frog reste la référence professionnelle : dans la configuration, activez l'option « Near Duplicates » et fixez le seuil à 90 % de similarité pour repérer les pages très proches. Le rapport généré croise contenu textuel, balise title, balise meta description et structure Hn. Sur un site de moins de 500 URLs, la version gratuite suffit. Au-delà, la licence payante est rapidement rentabilisée. Siteliner est une alternative gratuite plus simple, limitée à 250 pages par scan, parfaite pour un site vitrine standard. Les deux outils produisent un rapport hiérarchisé qui sert directement de feuille de route pour la réécriture.
Interface Screaming Frog pour la détection de doublons
Détecter le plagiat externe
Le plagiat seo subi représente une menace plus rare mais réelle, surtout pour les sites qui publient régulièrement du contenu de qualité. Trois outils couvrent ce besoin : Copyscape pour des vérifications page par page (gratuit en version limitée), Quetext pour une détection plus fine incluant les paraphrases générées par IA, et Copyleaks pour les sites éditoriaux à fort volume. La procédure, si un site tiers a effectivement repris votre contenu, suit trois étapes : contact direct du propriétaire du site (souvent suffisant), signalement à l'hébergeur en cas de refus, puis dépôt d'une notification DMCA auprès de Google en dernier recours. Cette dernière option déclasse ou désindexe la page copieuse en quelques jours.
Plan d'action en 7 étapes pour éliminer le contenu dupliqué
Savoir comment éviter le contenu dupliqué sur un site vitrine demande une feuille de route claire et priorisée par ratio impact / effort. Les chantiers techniques produisent en général 70 % du gain pour 30 % de l'effort, alors que la réécriture éditoriale demande l'inverse. Voici les sept étapes qui structurent un nettoyage complet, de la première intervention technique au maintien dans la durée.
Feuille de route en 7 étapes

Plan d'action en 7 étapes priorisé par ratio impact / effort
| Étape | Effort | Impact | Délai de résultat |
|---|---|---|---|
| 1. Consolider variantes d'URL (301) | Faible | Élevé | 2-4 semaines |
| 2. Déclarer rel=canonical | Faible | Élevé | 2-6 semaines |
| 3. Générer sitemap XML propre | Faible | Moyen | 1-3 semaines |
| 4. Noindex sur pages utilitaires | Faible | Moyen | 2-4 semaines |
| 5. Réécrire fiches dupliquées | Élevé | Très élevé | 4-12 semaines |
| 6. Gérer paramètres URL | Moyen | Moyen | 2-4 semaines |
| 7. Surveillance mensuelle | Faible (récurrent) | Élevé long terme | Continu |
Conseil du coach
Étapes techniques prioritaires
Les quatre premières étapes sont strictement techniques et doivent être engagées en priorité. Premièrement, redirections 301 sur toutes les variantes : forcer HTTPS, choisir entre www et non-www, normaliser le slash final, rediriger les anciennes URLs vers les nouvelles. Deuxièmement, balise rel=canonical sur chaque page, pointant vers sa propre version officielle pour neutraliser les paramètres parasites. Troisièmement, sitemap XML propre qui ne liste que les URLs canoniques (jamais les variantes), à soumettre dans la Search Console. Quatrièmement, noindex sur les pages utilitaires sans valeur SEO : panier, page de remerciement, résultats de recherche interne, archives par tag ou par auteur. Ce traitement combiné réduit l'impact du contenu dupliqué et autorité de domaine parce qu'il consolide tout le jus SEO sur les pages qui en ont vraiment besoin.
Étapes éditoriales : réécriture intelligente
L'étape cinq est la plus exigeante : réécrire les pages identifiées comme dupliquées. La règle empirique de 30 % de réécriture minimum n'est plus suffisante en 2026 ; il vaut mieux viser une réécriture complète pour les pages stratégiques. Pour comment éviter le contenu dupliqué sur un site vitrine durablement, trois leviers font la différence : élargir le champ sémantique (ajouter des sous-thèmes, des questions, des cas d'usage), intégrer des éléments uniques (témoignages clients, données chiffrées internes, photos originales, captures d'écran), et adapter la rédaction au persona local visé. Toutes les pages ne méritent pas le même effort : priorisez celles qui génèrent ou pourraient générer des demandes de contact. Une page « contact » dupliquée est anecdotique ; une page « service principal × ville principale » dupliquée coûte cher.
Mettre en place une surveillance durable
Le contenu dupliqué référencement se traite, mais il revient. Migrations, ajouts de nouveaux modules, refontes partielles, nouveaux paramètres de tracking : chaque évolution du site peut régénérer des doublons. La routine recommandée combine quatre actions : un contrôle mensuel du rapport Indexation de la Search Console, une alerte Copyscape Pro qui surveille les copies externes, un audit trimestriel complet via Screaming Frog ou un prestataire externe, et une intégration des indicateurs duplicate dans le reporting SEO global. Cette surveillance évite les rechutes silencieuses et permet de détecter en quelques jours toute dérive technique ou éditoriale. C'est aussi ce qui permet de cumuler sur le long terme les gains obtenus à chaque cycle de nettoyage.
L'essentiel à retenir
Combien le duplicate content coûte vraiment à votre entreprise
Le plagiat seo et le duplicate content interne ne sont pas seulement des sujets techniques : ce sont des sujets de chiffre d'affaires. Pour un dirigeant de PME ou une profession libérale, la bonne question n'est pas « est-ce grave ? » mais « combien ça me coûte chaque mois ? ». L'expérience des audits réalisés par notre équipe permet de chiffrer cet impact avec une précision suffisante pour décider rapidement.
Impact business du duplicate content
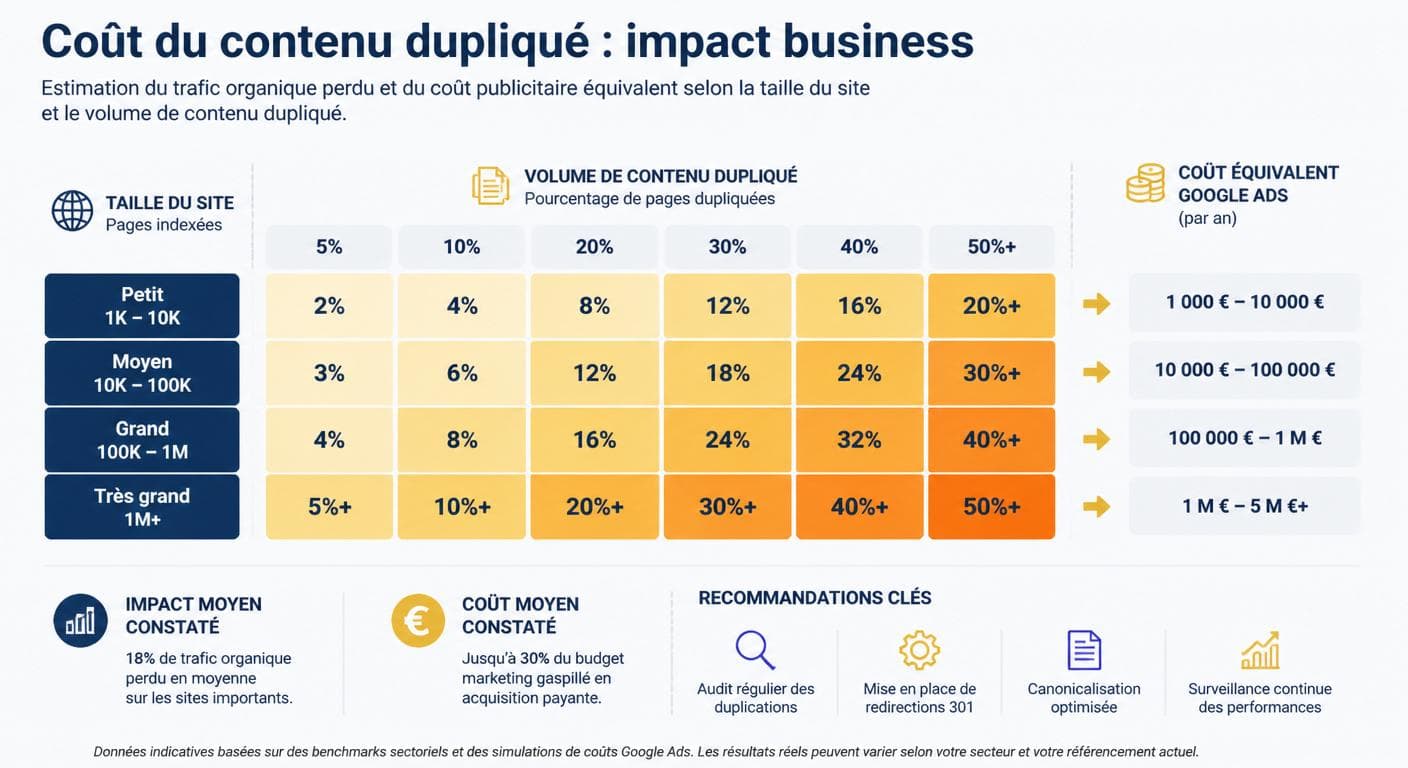
Impact business estimé du duplicate content selon la taille du site
| Taille du site | Volume de doublons typique | Perte de trafic estimée | Équivalent Google Ads mensuel |
|---|---|---|---|
| Site vitrine TPE (10-20 pages) | 30-50 URLs dupliquées | 15-25 % | 200 à 600 € |
| Profession libérale multi-zones | 50-100 URLs dupliquées | 20-35 % | 500 à 1 500 € |
| PME services 50+ pages | 100-300 URLs dupliquées | 25-45 % | 1 500 à 4 000 € |
| E-commerce 500+ produits | 500-2000 URLs dupliquées | 30-60 % | 3 000 à 15 000 € |
Conseil du coach
Le calcul devient plus parlant encore quand on intègre le maillage interne et l'autorité de domaine. Vous pouvez approfondir cette dimension stratégique avec notre guide complet sur l'audit SEO technique qui détaille les gains observés sur des sites de PME après correction des problèmes techniques majeurs.
Perte de trafic et coût d'opportunité
Le duplicate content seo se traduit directement en visites perdues. Une page mal positionnée à cause d'une dilution se retrouve en page 2 ou 3 de Google, ce qui équivaut concrètement à zéro trafic organique. Pour une profession libérale qui dépend d'une dizaine de requêtes locales, perdre la première position sur trois de ces requêtes peut représenter 30 à 50 demandes de devis mensuelles en moins. Pour un commerçant local, c'est l'équivalent d'une journée de fermeture par semaine, sans aucune compensation. La traduction business est immédiate : chiffre d'affaires manqué, dépendance accrue à la publicité payante, marge réduite.
Délai de récupération après nettoyage
Après mise en œuvre des correctifs, le duplicate content google met du temps à se résorber. Google doit recrawler les pages, prendre en compte les nouvelles balises canonical, désindexer les versions secondaires et repositionner la page canonique sur les requêtes cibles. Le cycle classique se déroule en trois phases : recrawl initial sous 2 à 4 semaines, prise en compte des canoniques entre 4 et 8 semaines, repositionnement progressif entre 8 et 12 semaines. Sur les audits suivis par notre équipe, les premiers gains de positions apparaissent généralement dès la quatrième semaine, avec une stabilisation au troisième mois.
Quand confier l'audit à un prestataire externe
La duplication de contenu seo peut se traiter en interne pour un site simple, mais plusieurs seuils justifient le recours à un prestataire. Au-delà de 50 pages, le crawl interne devient chronophage et la priorisation demande une expertise technique. Pour les sites multi-implantations, la gestion combinée du site, du Google Business Profile et des annuaires demande une vision d'ensemble difficile à tenir en interne. Pour les e-commerces, le volume de fiches produits et la complexité des paramètres d'URL imposent presque toujours un audit professionnel. Les critères de choix d'un prestataire reposent sur trois points : capacité à fournir un rapport actionnable (pas seulement un diagnostic), prise en charge complète de la mise en œuvre, et surveillance post-audit pour éviter les rechutes. Un service full-service qui couvre détection, correction et reporting est ce qui produit le meilleur retour sur investissement.
